Linux多线程编程
pthread库的使用
线程的创建和终止
| 线程函数 | 功能 | 类似的进程函数 |
|---|---|---|
| pthread_create | 创建一个线程 | fork |
| pthread_exit | 线程退出 | exit |
| pthread_join | 等待线程结束并回收内核资源 | wait |
| pthread_self | 获取线程id | getpid |
pthread库函数的错误处理
31char *strerror(int errnum);2补充:新版的errno不是全局变量
为了支持多线程,POSIX标准要求errno必须是线程安全的。这意味着每个线程需要有自己独立的errno实例,避免不同线程之间的干扰。因此,实现上errno可能不再是一个简单的全局变量,而是通过线程局部存储(Thread-Local Storage, TLS)来实现,每个线程拥有自己的errno副本。
尽管如此,返回值表示错误原因的设计已经固定下来了,考虑到兼容性,也不会做修改了。
线程的创建 并发性
31int pthread_create(pthread_t *thread, const pthread_attr_t *attr,3 void *(*start_routine) (void *), void *arg);61//获取本线程的tid2int main()3{4 printf("pid = %d,tid = %lu\n",getpid(),pthread_self());5 return 0;6}171//下面是一个不传递参数的版本2void * threadFunc(void *arg){3 printf("I am child thread, tid = %lu\n",4 pthread_self());5 return NULL;6}7int main()8{9 pthread_t tid;10 int ret = pthread_create(&tid,NULL,threadFunc,NULL);11 THREAD_ERROR_CHECK(ret,"pthread_create");12 printf("I am main thread, tid = %lu\n",13 pthread_self());14 sleep(1);15 //usleep(20);16 return 0;17}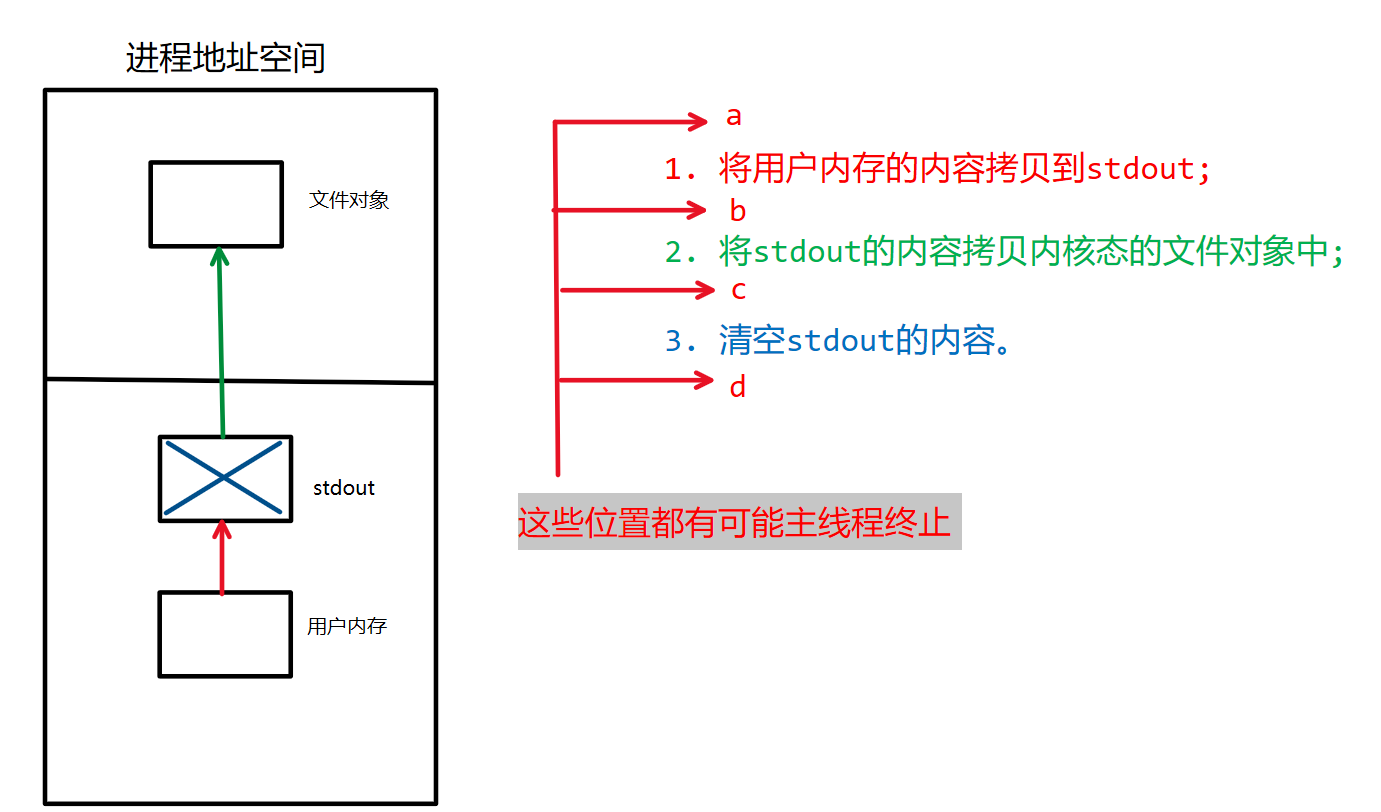
线程主动退出
11void pthread_exit(void *retval);161void * threadFunc(void *arg){2 printf("I am child thread, tid = %lu\n",3 pthread_self());4 //pthread_exit(NULL);和在线程入口函数return(NULL)等价5 printf("Can you see me?\n");6}7int main()8{9 pthread_t tid;10 int ret = pthread_create(&tid,NULL,threadFunc,NULL);11 THREAD_ERROR_CHECK(ret,"pthread_create");12 printf("I am main thread, tid = %lu\n",13 pthread_self());14 sleep(1);15 return 0;16}获取线程退出状态
11int pthread_join(pthread_t thread, void **retval);231void * threadFunc(void *arg){2 printf("I am child thread, tid = %lu\n",3 pthread_self());4 //pthread_exit(NULL);//相当于返回成一个8字节的05 //pthread_exit((void *)1);6 char *tret = (char *)malloc(20);7 strcpy(tret,"hello");8 return (void *)tret;9}10int main()11{12 pthread_t tid;13 int ret = pthread_create(&tid,NULL,threadFunc,NULL);14 THREAD_ERROR_CHECK(ret,"pthread_create");15 printf("I am main thread, tid = %lu\n",16 pthread_self());17 void *tret;//在调用函数中申请void*变量18 ret = pthread_join(tid,&tret);//传入void*变量的地址19 THREAD_ERROR_CHECK(ret,"pthread_join");20 //printf("tret = %ld\n", (long) tret);21 printf("tret = %s\n", (char *)tret);22 return 0;23}线程的取消和资源清理
线程的取消
11int pthread_cancel(pthread_t thread);111$man 7 pthreads2部分取消点:3 accept()4 close()5 connect()6 open()7 pthread_cond_timedwait()8 pthread_cond_wait()9 pthread_join()10 pthread_testcancel()11 read()xxxxxxxxxx211void * threadFunc(void *arg){2 printf("I am child thread, tid = %lu\n",3 pthread_self());4 return (void *)0;5}6int main()7{8 pthread_t tid;9 int ret = pthread_create(&tid,NULL,threadFunc,NULL);10 THREAD_ERROR_CHECK(ret,"pthread_create");11 printf("I am main thread, tid = %lu\n",12 pthread_self());13 void * pret;14 ret = pthread_cancel(tid);15 THREAD_ERROR_CHECK(ret,"pthread_cancel");16 ret = pthread_join(tid,&pret);17 THREAD_ERROR_CHECK(ret,"pthread_join");18 printf("thread return = %ld\n", (long) pret);19 return 0;20}21//可以发现pthread_cancel执行成功,因为获取的返回值是-1而不是正常退出的011void pthread_testcancel(void);171void *threadFunc(void *arg){2 while(1){3 pthread_testcancel();4 }5}6int main()7{8 pthread_t tid;9 pthread_create(&tid,NULL,threadFunc,NULL);10 sleep(1);11 printf("sleep over!\n");12 pthread_cancel(tid);13 void *ret;14 pthread_join(tid,&ret);15 printf("You die, ret = %ld\n", (long ) ret);16 return 0;17}线程资源清理
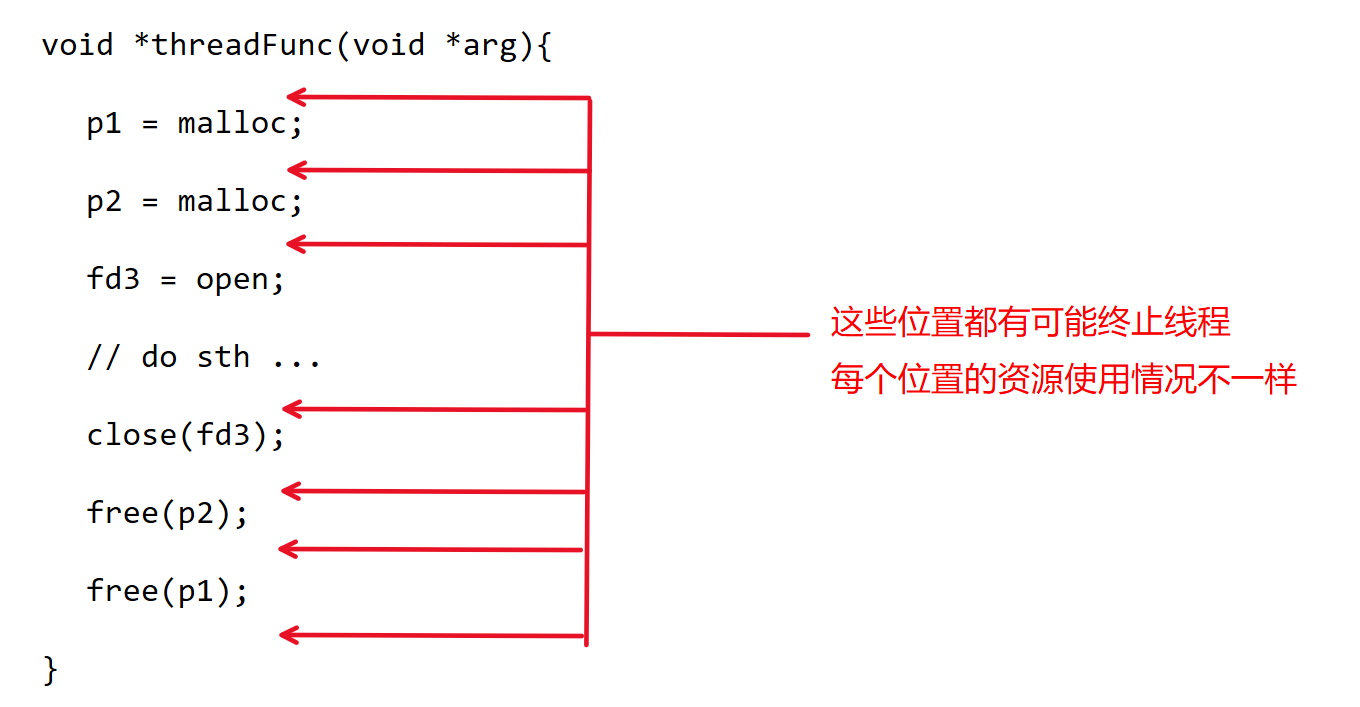
为了让线程无论在什么位置终止,都能够根据实际持有的资源情况来执行资源释放操作。pthread库引入了资源清理机制:
pthread库为每一个线程设计了一个资源清理函数栈栈当中的每一个元素是一个函数指针和一个参数(这个函数可以用来释放占用的资源,称为清理函数)
用户每次申请资源之后,需要立刻执行压栈操作
用户的资源释放行为会被替换成弹栈
pthread_cleanup_push和pthread_cleanup_pop函数可以用来管理资源清理函数栈。
31void pthread_cleanup_push(void (*routine)(void *),2 void *arg);3void pthread_cleanup_pop(int execute);pthread_cleanup_push负责将清理函数压栈,这个栈会在下列情况下弹出:
线程因为取消而终止时,所有清理函数按照后进先出的顺序从栈中弹出并执行。
线程调用
pthread_exit而主动终止时,所有清理函数按照后进先出的顺序从栈中弹出并执行。线程调用
pthread_clean_pop并且execute参数非0时,弹出栈顶的清理函数并执行。线程调用
pthread_clean_pop并且execute参数为0时,弹出栈顶的清理函数不执行。
值得特别注意的是:当线程在start_routine中执行return语句而终止的时候,清理函数不会弹栈!
371void freep1(void *arg){2 void *p1 = arg;3 printf("free p1!\n");4 free(p1);5}6void freep2(void *arg){7 void *p2 = arg;8 printf("free p2!\n");9 free(p2);10}11void closefd3(void *arg){ //包装函数,其参数和返回值固定12 int *pfd3 = (int *) arg;13 printf("close fd3!\n");14 close(*pfd3);//调用真正的清理行为15}16void *threadFunc(void *arg){17 void *p1 = malloc(4);18 pthread_cleanup_push(freep1,p1); //pthread_cleanup_push不是取消点!19 void *p2 = malloc(4);20 pthread_cleanup_push(freep2,p2);21 int fd3 = open("file1",O_RDWR|O_CREAT,0666);22 pthread_cleanup_push(closefd3,&fd3);23 printf("------------------------do something!\n");24 pthread_cleanup_pop(1);25 pthread_cleanup_pop(1);26 printf("------------------------\n");27 pthread_exit(NULL); // 无论在什么位置终止,线程都能根据实际持有的资源来执行释放行为。28 pthread_cleanup_pop(1);29}30int main(int argc, char *argv[])31{32 pthread_t tid;33 pthread_create(&tid,NULL,threadFunc,NULL);34
35 pthread_join(tid,NULL);36 return 0;37}POSIX要求pthread_cleanup_push和pthread_cleanup_pop必须成对出现在同一个作用域当中,主要是为了约束程序员在清理函数当中行为。下面是在/urs/include/pthread.h文件当中,线程清理函数的定义:
91 4 5/* Remove a cleanup handler installed by the matching pthread_cleanup_push.6 If EXECUTE is non-zero, the handler function is called. */7 9互斥锁
竞争条件
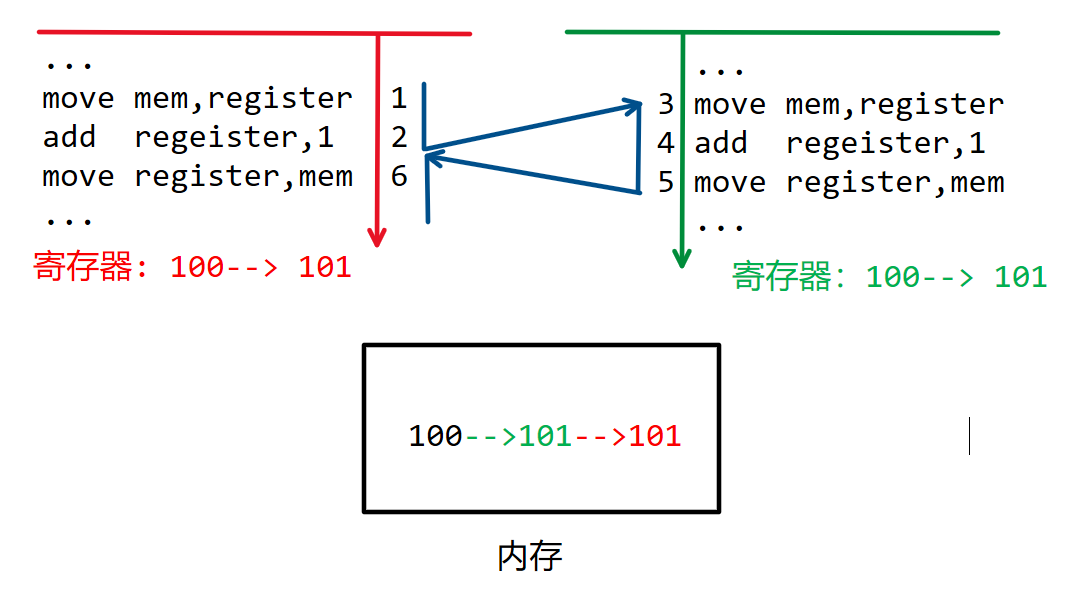
我们来看一下上图的执行过程:
现在有两个线程在并发执行,左边的线程先将内存当中100拷贝到本线程的寄存器当中
左边线程在对寄存器的数据做完增加操作的到数据101以后,触发了线程切换
右边线程也是先将内存的数据100拷贝到本线程的寄存器当中(由于左边线程没有写回内存,所以内存的数据还是100)
右边线程增加数据再将数据101写回内存
触发切换,左边线程继续将寄存器的数据101写回内存
上图最后的结果就是,两个线程各自做了一次加1,但是最终的结果当中却没有加2。那么,竞争条件产生的直接原因也就很明显了:当内存设备的数据和寄存器的数据不一致的时候,发生了线程切换。假如我们想要解决竞争条件问题,最直接的解决方案就是控制线程切换的位置,只有在内存和寄存器数据一致的时候才允许发生切换,也就是说我们希望读取-修改-写回这个过程是原子的。
如何才能实现原子性呢?这里有很多种不同层次的解决方案:
硬件层面上的关中断、原子操作、内存屏障、缓存一致性协议等等;
操作系统层面上的信号量、锁等等;
软件层面的互斥算法,比如
Dekker算法、Peterson算法等等。
目前来说,解决竞争条件问题比较常见且实用的机制就是互斥锁。
互斥锁的基本使用
在多线程编程中,用来控制共享资源的最简单有效也是最广泛使用的机制就是mutex(MUTual EXclusion),即互斥锁。
互斥锁的数据类型是pthread_mutex_t,其本质是一个共享的标志位,它存在两种状态:未锁和已锁。在此基础上,互斥锁支持两个原语(原语是不可分割的操作的意思):
原子地测试并改为已锁状态,即所谓的加锁。当一个线程持有锁的时候,其余线程再尝试加锁时(包括自己再次加锁),会使自己陷入阻塞状态,直到锁被持有线程解锁才能恢复运行。所以锁在某个时刻永远不能被两个线程同时持有。
解锁,将锁的状态从已锁改成未锁。
创建锁并且让其处于未锁状态的方法有两种:
直接用
PHTREAD_MUTEX_INITIALIZER初始化一个pthread_mutex_t类型的变量,即静态初始化锁;而使用
pthread_mutex_init函数可以动态创建一个锁。动态创建锁的方式更加常见。
使用pthread_mutex_lock可以加锁,使用pthread_mutex_unlock可以解锁。使用pthread_mutex_destory可以销毁一个锁。
61pthread_mutex_t fastmutex = PTHREAD_MUTEX_INITIALIZER;2int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);3int pthread_mutex_destroy(pthread_mutex_t *mutex);4int pthread_mutex_lock(pthread_mutex_t *mutex);5int pthread_mutex_unlock(pthread_mutex_t *mutex);6int pthread_mutex_trylock(pthread_mutex_t *mutex);下面是一个使用锁来保护共享资源的例子。使用锁的原则有这样几个:
在访问共享资源之前,无论是读取还是写入共享资源,都要先加锁;
在访问共享资源之后,需要立即解锁;
从加锁到解锁之间的代码段称为临界区,在保证正确性的情况下,临界区越短越好。
此外,还有一个重要的编程规范:谁加锁,谁解锁。
321typedef struct shareRes_s {3 int num;4 pthread_mutex_t mutex;5}shareRes_t; // share resource6void *threadFunc(void *arg){7 shareRes_t * pshareRes = (shareRes_t *)arg;8 for(int i = 0; i < NUM; ++i){9 pthread_mutex_lock(&pshareRes->mutex);10 ++pshareRes->num;11 pthread_mutex_unlock(&pshareRes->mutex);12 }13 pthread_exit(NULL);14}15int main(int argc, char *argv[])16{17 shareRes_t shareRes;//在栈上申请一片内存18 shareRes.num = 0; //初始化19 pthread_mutex_init(&shareRes.mutex, NULL); //给锁做动态初始化20 pthread_t tid;21 pthread_create(&tid,NULL,threadFunc,&shareRes); // shareRes_t * --> void *22 for(int i = 0; i < NUM; ++i){23 pthread_mutex_lock(&shareRes.mutex);24 ++shareRes.num;25 pthread_mutex_unlock(&shareRes.mutex);26 }27 pthread_join(tid,NULL);28
29 printf("num = %d\n", shareRes.num);30 return 0;31}32
加锁和解锁的性能消耗

根据上图可以得出结论:加锁/解锁的时间开销只比访问寄存器和L1缓存大,比访问内存、磁盘和网络都要小,因此在绝大多数应用程序当中,加锁解锁的次数对于程序性能没有影响。相反地,使用互斥锁的性能风险,一般来源于临界区的长度——当某个线程的临界区太长的时候,该线程会一直持有锁,导致其他需要使用共享资源的线程均阻塞,影响了整个应用程序的性能。
非阻塞加锁
pthread_mutex_trylock函数可以用来非阻塞地加锁——假如互斥锁处于未锁状态,则加锁成功;假如互斥锁处于已锁状态,函数会直接报错并返回。
201typedef struct shareRes_s{2 pthread_mutex_t mutex;3} shareRes_t, *pShareRes_t;4void *threadFunc(void *arg){5 //pthread_mutex_lock(&((pShareRes_t)arg)->mutex); //这句指令是否注释会影响trylock的返回值6 puts("I am child thread");7}8int main()9{10 shareRes_t shared;11 pthread_t tid;12 pthread_mutex_init(&shared.mutex,NULL);13 pthread_create(&tid,NULL,threadFunc,&shared);14 sleep(1);15 int ret = pthread_mutex_trylock(&shared.mutex);16 printf("I am main thread, ret = %d\n", ret);17 pthread_mutex_unlock(&shared.mutex);18 pthread_join(tid,NULL);19 return 0;20}死锁 锁的属性
使用互斥锁的时候必须小心谨慎,尽量按照一定的规范使用。如果使用不当的话,很有可能会出现死锁问题。死锁是指一个或多个线程因争夺资源陷入无限等待的状态。例如,线程A持有锁L1并请求锁L2,而线程B持有锁L2并请求锁L1,双方都无法释放已持有的锁,导致程序停滞。
互斥条件(Mutual Exclusion):资源每次只能被一个线程占用。
持有并等待(Hold and Wait):线程持有至少一个资源,同时等待其他资源。
不可剥夺(No Preemption):资源只能由持有者主动释放,不可强行剥夺。
循环等待(Circular Wait):存在线程-资源的环形等待链(如T1等待T2占用的资源,T2等待T1占用的资源)。
常见的死锁场景有这样几种:
双锁交叉请求:线程t1先加锁M1,再加锁M2;线程t2先加锁M2,再加锁M1;如果加锁时机不对,t1锁上M1之后t2也锁上了M2,此时会触发永久等待;
持有锁的线程终止:线程t1先加锁M,然后终止,线程t2随后加锁M,将会陷入永久等待;
持有锁的线程重复加锁:线程t1先加锁M,然后t1再加锁M,此时会永久等待。
为了一定程度上避免第三种死锁场景,用户可以使用pthread_mutexattr_settype函数修改锁属性:
检错锁在重复加锁时会触发报错。
可重入锁在重复加锁时不会死锁,只是会增加锁的引用计数,解锁时也只是减少锁的引用计数。
xxxxxxxxxx1typedef struct shareRes_s{2 pthread_mutex_t mutex;3} shareRes_t, *pShareRes_t;4void *threadFunc(void *arg){5 pShareRes_t p = (pShareRes_t)arg;6 pthread_mutex_lock(&p->mutex);7 puts("fifth");8 pthread_mutex_unlock(&p->mutex);9}10int main()11{12 shareRes_t shared;13 int ret;14 pthread_mutexattr_t mutexattr;15 pthread_mutexattr_init(&mutexattr);16 //ret = pthread_mutexattr_settype(&mutexattr,PTHREAD_MUTEX_ERRORCHECK); //检错锁17 ret = pthread_mutexattr_settype(&mutexattr,PTHREAD_MUTEX_RECURSIVE); //可重入锁18 THREAD_ERROR_CHECK(ret,"pthread_mutexattr_settype");19 pthread_t tid;20 pthread_create(&tid,NULL,threadFunc,(void *)&shared);21 pthread_mutex_init(&shared.mutex,&mutexattr);22 ret = pthread_mutex_lock(&shared.mutex);23 THREAD_ERROR_CHECK(ret,"pthread_mute_lock 1");24 puts("first");25 ret = pthread_mutex_lock(&shared.mutex);26 THREAD_ERROR_CHECK(ret,"pthread_mute_lock 2");27 puts("second");28 pthread_mutex_unlock(&shared.mutex);29 puts("third");30 pthread_mutex_unlock(&shared.mutex);//两次加锁,要有两次解锁31 puts("forth");32 pthread_join(tid,NULL);33 return 0;34}互斥锁应该是最常见的线程同步工具,它的作用是保护共享资源,确保同一时间只有一个线程可以访问该资源。当一个线程获得了互斥锁之后,其他试图获取该锁的线程会被阻塞,直到锁被释放。互斥锁适用于那些需要独占访问资源的场景,比如修改全局变量或者操作数据结构的时候。
读写锁应该允许多个线程同时读取某个资源,但在写入时需要独占访问。也就是说,当没有写线程时,多个读线程可以同时获取锁;但一旦有写线程请求锁,后续的读线程会被阻塞,直到写线程完成操作。读写锁适用于读操作频繁而写操作较少的场景,这样可以提高并发性能。
自旋锁和互斥锁类似,都是用于保护临界区,但自旋锁在获取锁失败时不会让线程进入睡眠状态,而是会一直循环(自旋)检查锁是否被释放。这在多核系统中可能更高效,因为避免了线程切换的开销,但如果锁被长时间持有,会导致CPU资源的浪费。自旋锁适用于临界区很小且持有时间很短的场景,比如内核中的某些操作。
同步和条件变量
利用互斥锁实现同步
同步是指通过协调多个执行单元的行为,确保它们按照预期的逻辑顺序执行。理论上来说,利用互斥锁可以解决同步问题的:
假设我们的目标是无论按照什么样的顺序分配CPU,总能够让t1线程的A事件先执行而t2线程的B事件后执行;
我们先设置一个共享状态flag,用来记录A事件是否完成了。
t1线程的代码:执行A事件-->加锁-->修改状态flag-->解锁
t2线程的代码:先用死循环加锁flag,每次检查前后需要加锁解锁-->一旦flag有变,则离开死循环-->执行B事件。
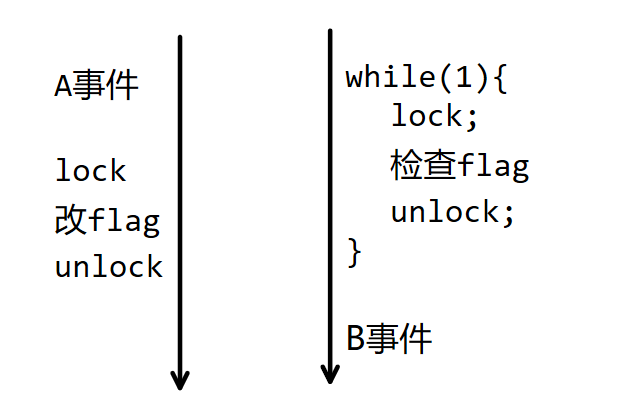
根据上图我们可知,无论t1线程和t2线程按照什么样的顺序交织执行,总是能够满足A先B后的要求。这样,我们就利用互斥锁来实现了同步机制。但是这种只依赖于互斥锁的方案也会存在问题,当t2线程占用CPU但是A事件并没有完成的情况下,t2会执行大量的重复的“加锁-检查条件不满足-解锁”的操作,也就是说不满足条件的线程会一致占用CPU,非常浪费资源。这种CPU资源的浪费的根本原因是竞争——即使本线程不具备继续运行的条件,也要时刻处于就绪状态抢占CPU。
条件变量
对于依赖于共享资源这种条件来控制线程之间的同步的问题,我们希望采用一种无竞争的方式让多个线程在共享资源处汇合——这就是条件变量要完成的目标。
条件变量提供了两个基本的原语:等待和唤醒。执行后事件的线程运行时可以等待,执行先事件的线程在做完事件之后可以唤醒其他线程。条件变量的使用是有一定的规范的:在使用条件变量的时候,由于CPU的分配顺序是随机的,所以可能会出现这样的情况——一个线程唤醒时另一个线程还没有进入等待,为了规避无限等待的场景,用户需要根据业务需求去设计一个状态/条件(一般是一个标志位)来表示事件是否已经完成的,这个状态是多线程共享的,故修改的时候必须加锁访问,这就意味着条件变量一定要配合锁来使用。
接下来我们来举一个条件变量的例子:
业务场景:假设有两个线程t1和t2并发运行,t1会执行A事件,t2会执行B事件,现在业务要求,无论t1或t2哪个线程先占用CPU,总是需要满足A先B后的同步顺序。
解决方案:
在t1和t2线程执行之前,先将状态初始化为A未执行。
t1线程执行A事件,执行完成以后先加锁,修改状态为B可执行,并唤醒条件变量,然后解锁(解锁和唤醒这两个操作可以交换顺序);
t2线程先加锁,然后检查状态:假如B不可执行,则B阻塞在条件变量上,当t2阻塞在条件变量以后,t2线程会解锁并陷入阻塞状态直到t1线程唤醒为止,t2被唤醒以后,会先加锁。接下来t2线程处于加锁状态,可以在解锁之后,再来执行B事件;而假如状态为B可执行,则t2线程处于加锁状态继续执行后续代码,也可以在解锁之后,再来执行B事件。
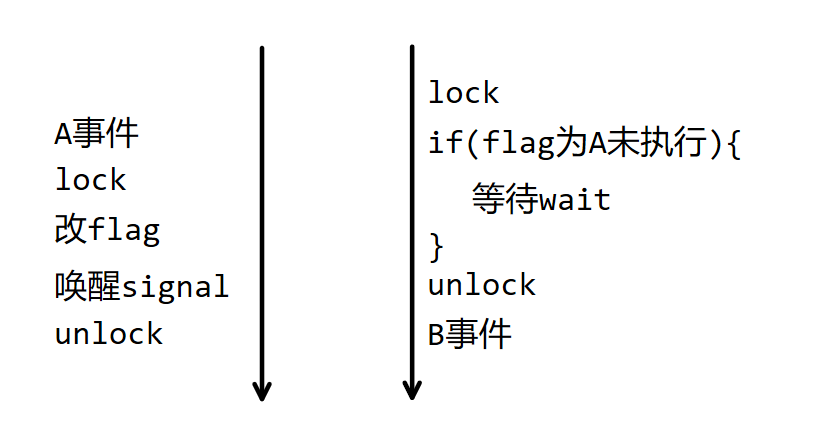
通过上面的设计,我们可以保证:无论t1和t2按照什么样的顺序交织执行,A事件总是先完成,B事件总是后完成——即使是比较极端的情况也是如此:比如t1一直占用CPU直到结束,那么t2占用CPU时,状态一定是B可执行,则不会陷入等待;又比如t2先一直占用CPU,t2检查状态时会发现状态为B不可执行,就会阻塞在条件变量之上,这样就要等到A执行完成以后,才能醒来继续运行。
条件变量相关的库函数
xxxxxxxxxx71pthread_cond_t cond = PTHREAD_COND_INITIALIZER;//静态初始化2int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);//动态初始化3int pthread_cond_signal(pthread_cond_t *cond); //唤醒至少一个线程4int pthread_cond_broadcast(pthread_cond_t *cond);//唤醒所有线程5int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);//等待6int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex, const struct timespec *abstime);//具有超时时限的等待7int pthread_cond_destroy(pthread_cond_t *cond);//条件变量销毁pthread_cond_wait的实现原理
pthread_cond_wait的执行流程如下:
进入阻塞之前:
检查互斥锁是否存在且处于已锁状态;
将本线程加入到唤醒队列当中;
解锁并将本线程陷入阻塞态;
在醒来之后(比如被pthread_cond_signal了)
将互斥锁加锁(可能会再次陷入等待);
函数返回
根据上述过程,我们会发现pthread_cond_wait在调用之前是已锁的,返回之后也是已锁的,在等待期间是未锁的。这样设计的原因如下:
pthread_cond_wait一般会配合状态使用,并且需要在if条件下执行,所以我们需要保证无论是否调用pthread_cond_wait,离开if结构之后都是已锁状态;pthread_cond_wait等待期间其他线程应该有能力修改状态,所以将锁解开。
451typedef struct shareRes_s {2 int flag; // flag 0 A可以执行 1 B可以执行3 pthread_mutex_t mutex;4 pthread_cond_t cond;5} shareRes_t;6void A(){7 printf("Before A\n");8 sleep(3);9 printf("After A\n");10}11void B(){12 printf("Before B\n");13 sleep(3);14 printf("After B\n");15}16void *threadFunc(void *arg){17 sleep(5);18 shareRes_t * pshareRes = (shareRes_t *)arg;19 pthread_mutex_lock(&pshareRes->mutex);20 if(pshareRes->flag != 1){21 pthread_cond_wait(&pshareRes->cond,&pshareRes->mutex);22 }23 pthread_mutex_unlock(&pshareRes->mutex);24 B();25 pthread_exit(NULL);26}27int main(int argc, char *argv[])28{29 shareRes_t shareRes;30 shareRes.flag = 0;31 pthread_mutex_init(&shareRes.mutex, NULL);32 pthread_cond_init(&shareRes.cond, NULL);33 34 pthread_t tid;35 pthread_create(&tid,NULL,threadFunc,&shareRes);36
37 A();38 pthread_mutex_lock(&shareRes.mutex);39 shareRes.flag = 1;40 pthread_cond_signal(&shareRes.cond);41 pthread_mutex_unlock(&shareRes.mutex);42 43 pthread_join(tid,NULL);44 return 0;45}下面是更加复杂的卖火车票的例子,我们除了拥有两个卖票窗口之外,还会有一个放票部门。
851typedef struct shareRes_s{2 pthread_mutex_t mutex;3 pthread_cond_t cond;4 int ticketNum;5} shareRes_t, *pshareRes_t;6void *sellTicket1(void *arg){7 sleep(1);//让setTicket先抢到锁8 pshareRes_t pshared = (pshareRes_t)arg;9 while(1){10 pthread_mutex_lock(&pshared->mutex);11 if(pshared->ticketNum > 0){12 printf("Before 1 sells tickets, ticketNum = %d\n", pshared->ticketNum);13 --pshared->ticketNum;14 if(pshared->ticketNum == 0){15 pthread_cond_signal(&pshared->cond);16 }17 usleep(500000);18 printf("After 1 sells tickets, ticketNum = %d\n", pshared->ticketNum);19 pthread_mutex_unlock(&pshared->mutex);20 usleep(200000);//等待一会,让setTicket抢到锁21 }22 else{23 pthread_mutex_unlock(&pshared->mutex);24 break;25 }26 }27 pthread_exit(NULL);28}29void *sellTicket2(void *arg){30 sleep(1);31 pshareRes_t pshared = (pshareRes_t)arg;32 while(1){33 pthread_mutex_lock(&pshared->mutex);34 if(pshared->ticketNum > 0){35 printf("Before 2 sells tickets, ticketNum = %d\n", pshared->ticketNum);36 --pshared->ticketNum;37 if(pshared->ticketNum == 0){38 pthread_cond_signal(&pshared->cond);39 }40 usleep(500000);41 printf("After 2 sells tickets, ticketNum = %d\n", pshared->ticketNum);42 pthread_mutex_unlock(&pshared->mutex);43 usleep(200000);44 }45 else{46 pthread_mutex_unlock(&pshared->mutex);47 break;48 }49 }50 pthread_exit(NULL);51}52void *setTicket(void *arg){53 pshareRes_t pshared = (pshareRes_t)arg;54 pthread_mutex_lock(&pshared->mutex);55 if(pshared->ticketNum > 0){56 printf("Set is waiting\n");57 int ret = pthread_cond_wait(&pshared->cond,&pshared->mutex);58 THREAD_ERROR_CHECK(ret,"pthread_cond_wait");59 }60 printf("add tickets\n");61 pshared->ticketNum = 10;62 pthread_mutex_unlock(&pshared->mutex);63 pthread_exit(NULL);64}65int main()66{67 shareRes_t shared;68 shared.ticketNum = 20;69 int ret;70 ret = pthread_mutex_init(&shared.mutex,NULL);71 THREAD_ERROR_CHECK(ret,"pthread_mutex_init");72 ret = pthread_cond_init(&shared.cond,NULL);73 THREAD_ERROR_CHECK(ret,"pthread_cond_init");74 pthread_t tid1,tid2,tid3;75 pthread_create(&tid3,NULL,setTicket,(void *)&shared);//希望setTicket第一个执行76 pthread_create(&tid1,NULL,sellTicket1,(void *)&shared);77 pthread_create(&tid2,NULL,sellTicket2,(void *)&shared);78 pthread_join(tid1,NULL);79 pthread_join(tid2,NULL);80 pthread_join(tid3,NULL);81 pthread_cond_destroy(&shared.cond);82 pthread_mutex_destroy(&shared.mutex);83 return 0;84}85
有些情况下,我们需要让因为不同的原因而陷入等待的线程等待在同一个条件变量下,这样的话,只要任何有意思的事件完成,我们就可以通过广播的方式来唤醒所有的线程,再让有条件执行的线程继续运行。
下面是这样的例子:在食堂当中存在一个窗口,同时贩卖两种食材黄焖鸡和猪脚饭,所有的学生只能排在一个队列里面。每个学生只能选择一种食物,食堂窗口每一次也只能完成一份食物。我们需要设计一个合理的流程,来确保每个学生都在自己想要的食物到来以后离开队列。
671typedef struct shareRes_s {2 int food; // 0 没有食物 1 黄焖鸡 2 猪脚饭3 pthread_mutex_t mutex;4 pthread_cond_t cond; // 1个条件变量就够用了5} shareRes_t;6void * student1(void *arg){7 shareRes_t * pshareRes = (shareRes_t *)arg;8 pthread_mutex_lock(&pshareRes->mutex);9 while(pshareRes->food != 1){ // while取代if 是为了兼容虚假唤醒10 printf("没有黄焖鸡, 学生1等待!\n");11 pthread_cond_wait(&pshareRes->cond,&pshareRes->mutex);12 printf("学生1 醒来!\n");13 }14 printf("黄焖鸡真的来了!\n");15 pshareRes->food = 0;16 pthread_mutex_unlock(&pshareRes->mutex);17 pthread_exit(NULL);18}19void * student2(void *arg){20 shareRes_t * pshareRes = (shareRes_t *)arg;21 pthread_mutex_lock(&pshareRes->mutex);22 while(pshareRes->food != 2){ // while取代if 是为了兼容虚假唤醒23 printf("没有猪脚饭, 学生2等待!\n");24 pthread_cond_wait(&pshareRes->cond,&pshareRes->mutex);25 printf("学生2 醒来!\n");26 }27 printf("猪脚饭真的来了!\n");28 pshareRes->food = 0;29 pthread_mutex_unlock(&pshareRes->mutex);30 pthread_exit(NULL);31
32}33int main(int argc, char *argv[])34{35 shareRes_t shareRes;36 shareRes.food = 0;37 pthread_mutex_init(&shareRes.mutex,NULL);38 pthread_cond_init(&shareRes.cond,NULL);39 40 pthread_t tid1,tid2;41 pthread_create(&tid1,NULL,student1,&shareRes);42 pthread_create(&tid2,NULL,student2,&shareRes);43 44 while(1){45 int food;46 scanf("%d", &food);47
48 pthread_mutex_lock(&shareRes.mutex);49 shareRes.food = food;50 if(food == 0){51 printf("逗你玩!\n");52 }53 else if(food == 1){54 printf("来了 黄焖鸡!\n");55 }56 else if(food == 2){57 printf("来了 猪脚饭!\n");58 }59 pthread_cond_broadcast(&shareRes.cond);60 pthread_mutex_unlock(&shareRes.mutex);61 }62 pthread_join(tid1,NULL);63 pthread_join(tid2,NULL);64 return 0;65}66
67
线程的属性
在线程创建的时候,用户可以给线程指定一些属性,用来控制线程的调度情况、CPU绑定情况、屏障、线程调用栈和线程分离等属性。这些属性可以通过一个pthread_attr_t类型的变量来控制,可以使用pthread_attr_set系列设置属性,然后可以传入pthread_create函数,从控制新建线程的属性。
在这里,我们以pthread_attr_setdetachstate为例子演示如何设置线程的属性。
161void * threadFunc(void *arg){2 return NULL;3}4int main()5{6 pthread_t tid;7 pthread_attr_t tattr;8 pthread_attr_init(&tattr);9 pthread_attr_setdetachstate(&tattr,PTHREAD_CREATE_DETACHED);10 int ret = pthread_create(&tid,&tattr,threadFunc,NULL);11 THREAD_ERROR_CHECK(ret,"pthread_create");12 ret = pthread_join(tid,NULL);13 THREAD_ERROR_CHECK(ret,"pthread_join");14 pthread_attr_destroy(&tattr);15 return 0;16}分离属性影响一个线程的终止状态是否能被其他线程使用pthread_join函数捕获终止状态。如果一个线程设置了分离属性,那么另一个线程使用pthread_join时会返回一个报错。
线程安全
由于多线程之间是共享同一个进程地址空间,所以多线程在访问共享数据的时候会出现竞争问题,这个问题不只会发生在用户自定义函数中,在一些库函数执行中也可能会出现竞争问题。有些库函数在设计的时候会申请额外的内存,或者会在静态区域分配数据结构——一个典型的库函数就是ctime。ctime函数会把日历时间字符串存储在静态区域。
221void * threadFunc(void *arg){2 time_t now;3 time(&now);4 char *p = ctime(&now);5 printf("child ptime = %s\n",p);6 sleep(5);7 printf("child ptime = %s\n",p);8 pthread_exit(NULL);9}10int main()11{12 pthread_t tid;13 int ret = pthread_create(&tid,NULL,threadFunc,NULL);14 THREAD_ERROR_CHECK(ret,"pthread_create");15 sleep(2);16 time_t mainNow;17 time(&mainNow);18 printf("main time = %s\n",ctime(&mainNow));19 ret = pthread_join(tid,NULL);20 THREAD_ERROR_CHECK(ret,"pthread_join");21 return 0;22}在上述例子中的,p指向的区域是静态的,所以即使子线程没有作任何修改,但是因为主线程会调用ctime修改静态区域的字符串,子线程两次输出的结构会有不同。使用ctime_r可以避免这个问题,ctime_r函数会增加一个额外指针参数,这个指针可以指向一个线程私有的数据,比如函数栈帧内,从而避免发生竞争问题。
241void *threadFunc(void *arg){2 time_t now;3 time(&now);4 char buf[256];5 char *p = ctime_r(&now,buf);6 printf("child ptime = %s\n",p);7 sleep(5);8 printf("child ptime = %s\n",p);9 pthread_exit(NULL);10}11int main()12{13 pthread_t tid;14 int ret = pthread_create(&tid,NULL,threadFunc,NULL);15 THREAD_ERROR_CHECK(ret,"pthread_create");16 sleep(2);17 char buf[256];18 time_t mainNow;19 time(&mainNow);20 printf("main time = %s\n",ctime_r(&mainNow,buf));21 ret = pthread_join(tid,NULL);22 THREAD_ERROR_CHECK(ret,"pthread_join");23 return 0;24}类似于ctime_r这种函数是线程安全的,如果额外数据是分配在线程私有区域的情况下,在多线程的情况下并发地使用这些库函数是不会出现并发问题的。在帮助手册中,库函数作者会说明线程的安全属性。